自然语言处理中需要将字、词或句子做embedding之前,一般会将对象转成一个字典中的索引,比如

假如,要处理字符级的索引问题,建议使用unicode的方式,这样可以直接获取唯一的编码
在Python中通过ord函数实现:
ord=(u"吃") # 21507
自然语言处理中需要将字、词或句子做embedding之前,一般会将对象转成一个字典中的索引,比如
假如,要处理字符级的索引问题,建议使用unicode的方式,这样可以直接获取唯一的编码
在Python中通过ord函数实现:
ord=(u"吃") # 21507
资源描述框架(RDF)是一套万维网委员会(W3C)推荐的描述资源的标准。什么是资源?这实在是一个很有深度的问题并且对它的准确定义也一直是一个争辩的论题。对我们来说,它是所有我们能够识别的东西。比如,你是一个资源,同样你的个人主页、这篇教程、数字1和Moby Dick的《The Greath White》。
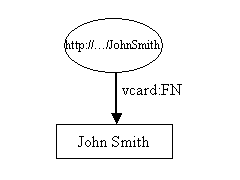
这篇教程,我们使用的所有例子都是关于人的,介绍了一个使用RDF做VCARDS陈述的方式。RDF的表现格式最好是通过节点和弧构成的图,如下所示,一个简单的vcard在RDF里面可以看成这样:
Google 全球商机洞察(Global Market Finder)是谷歌基于搜索信息、关键词广告和谷歌翻译推出的一款洞察全球商机的服务。在这服务中,谷歌大量的搜索、关键词竞价广告再一次被深度挖掘,通过对这些信息的区域划分来获取全球市场的竞争关系,而其中不同地域不同的用词问题,通过谷歌翻译做技术解决,确实是该项目的最佳配合点。这个2013年出来的成果,虽然今天才看到,还是很赞的。自己本身是做自动对齐不同语言文本的语料,其中关键词的自动对齐在技术上也解决了,所以对于解决方案的建立提供了一个很好的参考。 (更多…)
曾经在法国克莱蒙费朗国际短片节看过一个9宫格漫画,是了一套抢劫银行的画面:
如果没有场景,我们都不知道是在抢银行;
如果没有道具,抢劫的枪都找不到;
如果没有服装,演员们可能都是光PP的;
如果没有导演,影片都不知道在干嘛;
如果没有录音,大家只能靠手语来笔画;
如果没有技术,画面可能根本不知道是什么;
如果没有编剧,银行职员换个位置抢劫匪;
如果没有制片,劫匪可能拿着水枪来抢劫;
如果没有演员,大概只能看到空空的场景。
影院追求利益而丢弃人文,停止放映片尾字幕反映了影院对电影制作中各个岗位的不认同。若以蝴蝶效应来说,也会影响社会对这些岗位的冷落。
对于影院,也许99%的观众会觉得片尾太枯燥乏味,早早离场,但是也有1%的观众在乎这些。
对于影院,也许每部片子提早10分钟,一天就能多放一部片子,但是每次将以1%的速度流失观众。
对于观众,也许片尾可能很长,但是有美美的片尾曲等着;
对于观众,也许片尾很乏味,但是也会有彩蛋等着;
对于我们大家,也许我们身边的亲人、朋友,就有从事或将从事电影制作中的某个岗位,多一份了解,多一份关心。
该例读取下面三个IRI的内容,并返回RDF数据。这个例子比较有意思的是能够在
数据库里面创建一个Graph。
IRI:
http://kidehen.idehen.net/dataspace/person/kidehen#this
http://www.w3.org/People/Berners-Lee/card#i
http://demo.openlinksw.com/dataspace/person/demo#this
import org.apache.jena.query.Query;
import org.apache.jena.query.QueryFactory;
import org.apache.jena.query.QuerySolution;
import org.apache.jena.query.ResultSet;
import org.apache.jena.rdf.model.RDFNode;
import virtuoso.jena.driver.*;
public class VirtuosoSPARQLExample2 {
/**
* Executes a SPARQL query against a virtuoso url and prints results.
*/
public static void main(String[] args) {
String url;
if(args.length == 0)
url = "jdbc:virtuoso://localhost:1111";
else
url = args[0];
/* STEP 1 */
/*
* 这里添加"Example2"后,类似于打开一个Graph叫做"Example2",,
* 如果没有会自动生成一个名为"Example2"的图
*/
VirtGraph graph = new VirtGraph ("Example2", url, "dba", "dba");
/* STEP 2 */
/* Load data to Virtuoso */
//清除"Example2" Graph
graph.clear ();
/*
* 这里是读取IRI的Graph并存储到服务器的"Example2"
* 这里的读取,类似于在Web端在Quad Store Upload上的操作类似
* 如果网络连接不了,可以尝试删除下面的那些失败的内容
*/
System.out.print ("Begin read from 'http://www.w3.org/People/Berners-Lee/card#i' ");
graph.read("http://www.w3.org/People/Berners-Lee/card#i", "RDF/XML");
System.out.println ("\t\t\t Done.");
System.out.print ("Begin read from 'http://demo.openlinksw.com/dataspace/person/demo#this' ");
graph.read("http://demo.openlinksw.com/dataspace/person/demo#this", "RDF/XML");
System.out.println ("\t Done.");
System.out.print ("Begin read from 'http://kidehen.idehen.net/dataspace/person/kidehen#this' ");
graph.read("http://kidehen.idehen.net/dataspace/person/kidehen#this", "RDF/XML");
System.out.println ("\t Done.");
/* STEP 3 */
/* Select only from VirtGraph */
Query sparql = QueryFactory.create("SELECT ?s ?p ?o WHERE { ?s ?p ?o }");
/* STEP 4 */
VirtuosoQueryExecution vqe = VirtuosoQueryExecutionFactory.create (sparql, graph);
ResultSet results = vqe.execSelect();
while (results.hasNext()) {
QuerySolution result = results.nextSolution();
RDFNode graph_name = result.get("graph");
RDFNode s = result.get("s");
RDFNode p = result.get("p");
RDFNode o = result.get("o");
System.out.println(graph_name + " { " + s + " " + p + " " + o + " . }");
}
System.out.println("graph.getCount() = " + graph.getCount());
}
}
想要使用JAVA连接Virtuoso,我想最关心的额就是如何连接并查询,下面代码演示了如何操作
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.RDFNode;
import virtuoso.jena.driver.*;
public class VirtuosoSPARQLExample1 {
/*
* Executes a SPARQL query against a virtuoso url and prints results.
*/
public static void main(String[] args) {
String url;
if(args.length == 0)
//如果Virtuoso安装在本体,这个是默认的地址和端口
url = "jdbc:virtuoso://localhost:1111";
else
url = args[0];
/* STEP 1 */
//连接服务器,两个“dba”分别是账号和密码,是初始状态Virtuoso的默认值
VirtGraph set = new VirtGraph (url, "dba", "dba");
/* STEP 2 */
/* STEP 3 */
/* Select all data in virtuoso */
//给出查询语句,这里使用的是Jena框架里的
Query sparql = QueryFactory.create("SELECT * WHERE { GRAPH ?graph { ?s ?p ?o } } limit 100");
/* STEP 4 */
//在服务器"set"上执行查询语句"sparql"
VirtuosoQueryExecution vqe = VirtuosoQueryExecutionFactory.create (sparql, set);
//获取结果,这些就和Jena的操作一模一样了
ResultSet results = vqe.execSelect();
while (results.hasNext()) {
QuerySolution result = results.nextSolution();
RDFNode graph = result.get("graph");
RDFNode s = result.get("s");
RDFNode p = result.get("p");
RDFNode o = result.get("o");
System.out.println(graph + " { " + s + " " + p + " " + o + " . }");
}
}
}
Virtuoso Jena Provider是一个在Jena框架下的控制RDF图存储的程序。它使得任意一个语义网的应用能够通过Jena RDF框架直接请求Virtuoso RDF存储的数据。在这篇文章中,将会介绍一下如何使用该程序。

Virtuoso是一个管理多类型的数据库系统,他支持RDF的存储同时也支持SPARQL的查询,并且在众多评测结果都名列前茅,在前一篇文章写了《Virtuoso 安装 – Ubuntu环境》,这篇会给出一个例子如何上传自己的RDF,同时进行Sparql的查询。
OpenLink Virtuoso是下一代的通用服务器和业务管理器,它为新一代网络的开发和部署提供了遍历,能够将不同数据库和数据源的数据连接起来。在知识库领域,他支持RDF和SPARQL查询,他优越的性能得到了学术界的认同,大量的评测结果,它都名列前茅,属于开源软件中值得推荐的一款处理RDF的数据库系统。
(更多…)